1. 命令链
Groovy 允许您在顶级语句的方法调用参数周围省略括号。“命令链”功能通过允许我们链接此类无括号的方法调用来扩展此功能,既不需要参数周围的括号,也不需要链式调用之间的点。一般思想是 a b c d 这样的调用实际上等同于 a(b).c(d)。这也适用于多个参数、闭包参数,甚至是命名参数。此外,此类命令链也可以出现在赋值的右侧。让我们看一些这种新语法支持的示例
// equivalent to: turn(left).then(right)
turn left then right
// equivalent to: take(2.pills).of(chloroquinine).after(6.hours)
take 2.pills of chloroquinine after 6.hours
// equivalent to: paint(wall).with(red, green).and(yellow)
paint wall with red, green and yellow
// with named parameters too
// equivalent to: check(that: margarita).tastes(good)
check that: margarita tastes good
// with closures as parameters
// equivalent to: given({}).when({}).then({})
given { } when { } then { }也可以在链中使用不带参数的方法,但在这种情况下,需要括号
// equivalent to: select(all).unique().from(names)
select all unique() from names如果您的命令链包含奇数个元素,则该链将由方法/参数组成,并以最终属性访问结束
// equivalent to: take(3).cookies
// and also this: take(3).getCookies()
take 3 cookies这种命令链方法为现在可以用 Groovy 编写的更广泛的 DSL 开辟了有趣的可能性。
上面的示例说明了使用基于命令链的 DSL,但没有说明如何创建它。您可以使用多种策略,但为了说明如何创建这样的 DSL,我们将展示几个示例——首先使用映射和闭包
show = { println it }
square_root = { Math.sqrt(it) }
def please(action) {
[the: { what ->
[of: { n -> action(what(n)) }]
}]
}
// equivalent to: please(show).the(square_root).of(100)
please show the square_root of 100
// ==> 10.0作为第二个示例,考虑如何编写一个 DSL 以简化您现有的 API 之一。也许您需要将此代码展示给可能不是核心 Java 开发人员的客户、业务分析师或测试人员。我们将使用 Google Guava 库项目中的 Splitter,因为它已经有一个很好的流式 API。以下是我们如何直接使用它
@Grab('com.google.guava:guava:r09')
import com.google.common.base.*
def result = Splitter.on(',').trimResults(CharMatcher.is('_' as char)).split("_a ,_b_ ,c__").iterator().toList()对于 Java 开发人员来说,它读起来相当好,但如果这不是您的目标受众,或者您需要编写许多这样的语句,它可能会被认为有点冗长。同样,编写 DSL 有很多选择。我们将使用映射和闭包来保持简单。我们首先编写一个帮助方法
@Grab('com.google.guava:guava:r09')
import com.google.common.base.*
def split(string) {
[on: { sep ->
[trimming: { trimChar ->
Splitter.on(sep).trimResults(CharMatcher.is(trimChar as char)).split(string).iterator().toList()
}]
}]
}现在,代替我们原始示例中的这一行
def result = Splitter.on(',').trimResults(CharMatcher.is('_' as char)).split("_a ,_b_ ,c__").iterator().toList()我们可以这样写
def result = split "_a ,_b_ ,c__" on ',' trimming '_\'2. 运算符重载
Groovy 中的各种运算符被映射到对象的常规方法调用。
这允许您提供自己的 Java 或 Groovy 对象,这些对象可以利用运算符重载。下表描述了 Groovy 中支持的运算符及其映射到的方法。
| 运算符 | 方法 |
|---|---|
|
a.plus(b) |
|
a.minus(b) |
|
a.multiply(b) |
|
a.power(b) |
|
a.div(b) |
|
a.mod(b) |
|
a.or(b) |
|
a.and(b) |
|
a.xor(b) |
|
a.next() |
|
a.previous() |
|
a.getAt(b) |
|
a.putAt(b, c) |
|
a.leftShift(b) |
|
a.rightShift(b) |
|
a.rightShiftUnsigned(b) |
|
b.isCase(a) |
|
a.asBoolean() |
|
a.bitwiseNegate() |
|
a.negative() |
|
a.positive() |
|
a.asType(b) |
|
a.equals(b) |
|
! a.equals(b) |
|
a.compareTo(b) |
|
a.compareTo(b) > 0 |
|
a.compareTo(b) >= 0 |
|
a.compareTo(b) < 0 |
|
a.compareTo(b) <= 0 |
3. 脚本基类
3.1. Script 类
Groovy 脚本总是编译成类。例如,一个像这样简单的脚本
println 'Hello from Groovy'被编译成一个扩展抽象类 groovy.lang.Script 的类。这个类包含一个名为 run 的抽象方法。当脚本被编译时,它的主体将成为 run 方法,而脚本中找到的其他方法则在实现类中找到。Script 类通过 Binding 对象为与应用程序集成提供基本支持,如下例所示
def binding = new Binding() (1)
def shell = new GroovyShell(binding) (2)
binding.setVariable('x',1) (3)
binding.setVariable('y',3)
shell.evaluate 'z=2*x+y' (4)
assert binding.getVariable('z') == 5 (5)| 1 | 绑定用于在脚本和调用类之间共享数据 |
| 2 | GroovyShell 可以与此绑定一起使用 |
| 3 | 输入变量从调用类内部设置到绑定中 |
| 4 | 然后评估脚本 |
| 5 | 并且 z 变量已被“导出”到绑定中 |
这是一种在调用者和脚本之间共享数据的非常实用的方式,但在某些情况下可能不足或不实用。为此,Groovy 允许您设置自己的基本脚本类。基本脚本类必须扩展 groovy.lang.Script 并且是单一抽象方法类型
abstract class MyBaseClass extends Script {
String name
public void greet() { println "Hello, $name!" }
}然后可以在编译器配置中声明自定义脚本基类,例如
def config = new CompilerConfiguration() (1)
config.scriptBaseClass = 'MyBaseClass' (2)
def shell = new GroovyShell(this.class.classLoader, config) (3)
shell.evaluate """
setName 'Judith' (4)
greet()
"""| 1 | 创建自定义编译器配置 |
| 2 | 将基本脚本类设置为我们的自定义基本脚本类 |
| 3 | 然后使用该配置创建一个 GroovyShell |
| 4 | 然后脚本将扩展基本脚本类,直接访问 name 属性和 greet 方法 |
3.2. @BaseScript 注解
作为替代方案,也可以直接在脚本中使用 @BaseScript 注解
import groovy.transform.BaseScript
@BaseScript MyBaseClass baseScript
setName 'Judith'
greet()其中 @BaseScript 应该注解一个变量,其类型是基本脚本的类。或者,您可以将基本脚本类设置为 @BaseScript 注解本身的成员
@BaseScript(MyBaseClass)
import groovy.transform.BaseScript
setName 'Judith'
greet()3.3. 替代抽象方法
我们已经看到,基本脚本类是需要实现 run 方法的单一抽象方法类型。run 方法由脚本引擎自动执行。在某些情况下,拥有一个实现 run 方法但提供一个替代抽象方法用于脚本主体的基类可能很有趣。例如,基本脚本 run 方法可以在 run 方法执行之前执行一些初始化。这可以通过以下方式实现
abstract class MyBaseClass extends Script {
int count
abstract void scriptBody() (1)
def run() {
count++ (2)
scriptBody() (3)
count (4)
}
}| 1 | 基本脚本类应该定义一个(且只有一个)抽象方法 |
| 2 | run 方法可以被覆盖并在执行脚本主体之前执行任务 |
| 3 | run 调用抽象的 scriptBody 方法,该方法将委托给用户脚本 |
| 4 | 然后它可以返回脚本值之外的其他内容 |
如果执行此代码
def result = shell.evaluate """
println 'Ok'
"""
assert result == 1然后您将看到脚本已执行,但评估结果是基本类的 run 方法返回的 1。如果使用 parse 而不是 evaluate,则会更清楚,因为它允许您在同一个脚本实例上多次执行 run 方法
def script = shell.parse("println 'Ok'")
assert script.run() == 1
assert script.run() == 24. 为数字添加属性
在 Groovy 中,数字类型被视为与其他任何类型相同。因此,可以通过向数字添加属性或方法来增强数字。这在处理可测量量时非常方便,例如。有关如何在 Groovy 中增强现有类的详细信息,请参阅扩展模块部分或类别部分。
Groovy 中可以使用 TimeCategory 来演示这一点
use(TimeCategory) {
println 1.minute.from.now (1)
println 10.hours.ago
def someDate = new Date() (2)
println someDate - 3.months
}| 1 | 使用 TimeCategory,向 Integer 类添加了一个属性 minute |
| 2 | 类似地,months 方法返回一个 groovy.time.DatumDependentDuration,可以在计算中使用 |
类别是词法绑定的,这使得它们非常适合内部 DSL。
5. @DelegatesTo
5.1. 在编译时解释委托策略
@groovy.lang.DelegatesTo 是一个文档和编译时注解,旨在
-
文档化使用闭包作为参数的 API
-
为静态类型检查器和编译器提供类型信息
Groovy 语言是构建 DSL 的首选平台。使用闭包,创建自定义控制结构非常容易,同时创建构建器也很简单。想象一下,您有以下代码
email {
from 'dsl-guru@mycompany.com'
to 'john.doe@waitaminute.com'
subject 'The pope has resigned!'
body {
p 'Really, the pope has resigned!'
}
}实现此功能的一种方法是使用构建器策略,这意味着一个名为 email 的方法,它接受一个闭包作为参数。该方法可以将后续调用委托给一个实现 from、to、subject 和 body 方法的对象。同样,body 是一个接受闭包作为参数并使用构建器策略的方法。
实现这样的构建器通常以以下方式完成
def email(Closure cl) {
def email = new EmailSpec()
def code = cl.rehydrate(email, this, this)
code.resolveStrategy = Closure.DELEGATE_ONLY
code()
}EmailSpec 类实现了 from、to 等方法。通过调用 rehydrate,我们正在创建一个闭包副本,并为其设置 delegate、owner 和 thisObject 值。在此处设置所有者和 this 对象并不重要,因为我们将使用 DELEGATE_ONLY 策略,该策略表示方法调用将仅针对闭包的委托进行解析。
class EmailSpec {
void from(String from) { println "From: $from"}
void to(String... to) { println "To: $to"}
void subject(String subject) { println "Subject: $subject"}
void body(Closure body) {
def bodySpec = new BodySpec()
def code = body.rehydrate(bodySpec, this, this)
code.resolveStrategy = Closure.DELEGATE_ONLY
code()
}
}EmailSpec 类本身有一个 body 方法,它接受一个闭包,该闭包被克隆并执行。这就是我们在 Groovy 中所说的构建器模式。
我们展示的代码存在的一个问题是,email 方法的用户对闭包内允许调用的方法没有任何信息。唯一可能的信息来自方法文档。这有两个问题:首先,文档并非总是编写,即使编写了,也并非总是可用(例如,javadoc 未下载)。其次,它对 IDE 没有帮助。这里真正有趣的是,IDE 可以在开发人员进入闭包主体后,通过建议 email 类上存在的方法来帮助开发人员。
此外,如果用户在闭包中调用了一个未由 EmailSpec 类定义的方法,IDE 至少应该发出警告(因为运行时很可能会出现问题)。
上述代码还有一个问题是它与静态类型检查不兼容。类型检查可以让用户在编译时而不是运行时知道方法调用是否被授权,但如果您尝试对此代码执行类型检查
email {
from 'dsl-guru@mycompany.com'
to 'john.doe@waitaminute.com'
subject 'The pope has resigned!'
body {
p 'Really, the pope has resigned!'
}
}然后类型检查器将知道有一个 email 方法接受一个 Closure,但它会抱怨闭包**内部**的每个方法调用,因为例如 from 不是类中定义的方法。实际上,它是在 EmailSpec 类中定义的,它完全没有提示来帮助它知道闭包委托在运行时将是 EmailSpec 类型。
@groovy.transform.TypeChecked
void sendEmail() {
email {
from 'dsl-guru@mycompany.com'
to 'john.doe@waitaminute.com'
subject 'The pope has resigned!'
body {
p 'Really, the pope has resigned!'
}
}
}将因以下错误而编译失败
[Static type checking] - Cannot find matching method MyScript#from(java.lang.String). Please check if the declared type is correct and if the method exists.
@ line 31, column 21.
from 'dsl-guru@mycompany.com'
5.2. @DelegatesTo
由于这些原因,Groovy 2.1 引入了一个名为 @DelegatesTo 的新注解。此注解的目标是解决文档问题,它将让您的 IDE 知道闭包主体中预期的方法,它还将通过向编译器提供闭包主体中方法调用的潜在接收者的提示来解决类型检查问题。
想法是注解 email 方法的 Closure 参数
def email(@DelegatesTo(EmailSpec) Closure cl) {
def email = new EmailSpec()
def code = cl.rehydrate(email, this, this)
code.resolveStrategy = Closure.DELEGATE_ONLY
code()
}我们在这里所做的是告诉编译器(或 IDE),当方法被闭包调用时,此闭包的委托将被设置为 email 类型的一个对象。但仍然存在一个问题:默认的委托策略不是我们方法中使用的策略。所以我们将提供更多信息并告诉编译器(或 IDE)委托策略也已更改
def email(@DelegatesTo(strategy=Closure.DELEGATE_ONLY, value=EmailSpec) Closure cl) {
def email = new EmailSpec()
def code = cl.rehydrate(email, this, this)
code.resolveStrategy = Closure.DELEGATE_ONLY
code()
}现在,IDE 和类型检查器(如果您正在使用 @TypeChecked)都将知道委托和委托策略。这非常好,因为它既允许 IDE 提供智能补全,又将消除编译时存在的错误,而这些错误通常只有在运行时才知道程序的行为!
以下代码现在将通过编译
@TypeChecked
void doEmail() {
email {
from 'dsl-guru@mycompany.com'
to 'john.doe@waitaminute.com'
subject 'The pope has resigned!'
body {
p 'Really, the pope has resigned!'
}
}
}5.3. DelegatesTo 模式
@DelegatesTo 支持多种模式,我们将在本节中通过示例进行描述。
5.3.1. 简单委托
在此模式下,唯一必需的参数是 value,它指示我们委托给哪个类。仅此而已。我们告诉编译器,委托的类型将**始终**是 @DelegatesTo 文档化的类型(请注意,它可以是子类,但如果是子类,则子类定义的方法对类型检查器不可见)。
void body(@DelegatesTo(BodySpec) Closure cl) {
// ...
}5.3.2. 委托策略
在此模式下,您必须同时指定委托类**和**委托策略。如果闭包不使用默认委托策略 Closure.OWNER_FIRST 调用,则必须使用此模式。
void body(@DelegatesTo(strategy=Closure.DELEGATE_ONLY, value=BodySpec) Closure cl) {
// ...
}5.3.3. 委托给参数
在这个变体中,我们将告诉编译器,我们正在委托给方法的另一个参数。请看以下代码
def exec(Object target, Closure code) {
def clone = code.rehydrate(target, this, this)
clone()
}这里,将要使用的委托**不是**在 exec 方法内部创建的。实际上,我们采用方法的参数并委托给它。用法可能如下所示
def email = new Email()
exec(email) {
from '...'
to '...'
send()
}每个方法调用都委托给 email 参数。这是一种广泛使用的模式,@DelegatesTo 也通过伴随注解支持此模式
def exec(@DelegatesTo.Target Object target, @DelegatesTo Closure code) {
def clone = code.rehydrate(target, this, this)
clone()
}一个闭包被 @DelegatesTo 注解,但这次没有指定任何类。相反,我们使用 @DelegatesTo.Target 注解另一个参数。然后委托的类型在编译时确定。有人可能认为我们正在使用参数类型,在这种情况下是 Object,但这不是真的。请看这段代码
class Greeter {
void sayHello() { println 'Hello' }
}
def greeter = new Greeter()
exec(greeter) {
sayHello()
}请记住,这**无需**使用 @DelegatesTo 注解即可开箱即用。但是,为了让 IDE 知道委托类型,或者让**类型检查器**知道它,我们需要添加 @DelegatesTo。在这种情况下,它会知道 Greeter 变量的类型是 Greeter,因此即使 exec 方法没有明确将目标定义为 Greeter 类型,它也不会报告 sayHello 方法上的错误。这是一个非常强大的功能,因为它避免了您为不同的接收器类型编写多个版本的相同 exec 方法!
在此模式下,@DelegatesTo 注解还支持我们上面描述的 strategy 参数。
5.3.4. 多个闭包
在前面的示例中,exec 方法只接受一个闭包,但您可能有一些方法接受多个闭包
void fooBarBaz(Closure foo, Closure bar, Closure baz) {
...
}然后没有什么能阻止您用 @DelegatesTo 注解每个闭包
class Foo { void foo(String msg) { println "Foo ${msg}!" } }
class Bar { void bar(int x) { println "Bar ${x}!" } }
class Baz { void baz(Date d) { println "Baz ${d}!" } }
void fooBarBaz(@DelegatesTo(Foo) Closure foo, @DelegatesTo(Bar) Closure bar, @DelegatesTo(Baz) Closure baz) {
...
}但更重要的是,如果您有多个闭包**和**多个参数,则可以使用多个目标
void fooBarBaz(
@DelegatesTo.Target('foo') foo,
@DelegatesTo.Target('bar') bar,
@DelegatesTo.Target('baz') baz,
@DelegatesTo(target='foo') Closure cl1,
@DelegatesTo(target='bar') Closure cl2,
@DelegatesTo(target='baz') Closure cl3) {
cl1.rehydrate(foo, this, this).call()
cl2.rehydrate(bar, this, this).call()
cl3.rehydrate(baz, this, this).call()
}
def a = new Foo()
def b = new Bar()
def c = new Baz()
fooBarBaz(
a, b, c,
{ foo('Hello') },
{ bar(123) },
{ baz(new Date()) }
)| 此时,您可能会想知道为什么我们不使用参数名称作为引用。原因是信息(参数名称)并非总是可用(它只是调试信息),因此这是 JVM 的一个限制。 |
5.3.5. 委托给泛型类型
在某些情况下,指示 IDE 或编译器委托类型不是参数而是泛型类型会很有趣。想象一个在元素列表上运行的配置器
public <T> void configure(List<T> elements, Closure configuration) {
elements.each { e->
def clone = configuration.rehydrate(e, this, this)
clone.resolveStrategy = Closure.DELEGATE_FIRST
clone.call()
}
}然后可以使用任何列表调用此方法,如下所示
@groovy.transform.ToString
class Realm {
String name
}
List<Realm> list = []
3.times { list << new Realm() }
configure(list) {
name = 'My Realm'
}
assert list.every { it.name == 'My Realm' }为了让类型检查器和 IDE 知道 configure 方法在列表的每个元素上调用闭包,您需要以不同的方式使用 @DelegatesTo
public <T> void configure(
@DelegatesTo.Target List<T> elements,
@DelegatesTo(strategy=Closure.DELEGATE_FIRST, genericTypeIndex=0) Closure configuration) {
def clone = configuration.rehydrate(e, this, this)
clone.resolveStrategy = Closure.DELEGATE_FIRST
clone.call()
}@DelegatesTo 接受一个可选的 genericTypeIndex 参数,该参数指示将用作委托类型的泛型类型的索引。这**必须**与 @DelegatesTo.Target 结合使用,并且索引从 0 开始。在上面的示例中,这意味着委托类型是根据 List<T> 解析的,并且由于索引 0 处的泛型类型是 T 并且推断为 Realm,因此类型检查器推断委托类型将是 Realm 类型。
由于 JVM 的限制,我们使用的是 genericTypeIndex 而不是占位符 (T)。 |
5.3.6. 委托给任意类型
上述选项可能都无法表示您想要委托的类型。例如,让我们定义一个用对象参数化并定义一个返回另一种类型对象的方法的映射器类
class Mapper<T,U> { (1)
final T value (2)
Mapper(T value) { this.value = value }
U map(Closure<U> producer) { (3)
producer.delegate = value
producer()
}
}| 1 | 映射器类接受两个泛型类型参数:源类型和目标类型 |
| 2 | 源对象存储在一个最终字段中 |
| 3 | map 方法要求将源对象转换为目标对象 |
如您所见,map 方法的签名没有提供有关闭包将操作哪个对象的信息。阅读方法体,我们知道它将是 value,其类型为 T,但 T 在方法签名中找不到,因此我们面临一种情况,即 @DelegatesTo 的任何可用选项都不适用。例如,如果我们尝试静态编译此代码
def mapper = new Mapper<String,Integer>('Hello')
assert mapper.map { length() } == 5然后编译器将失败并显示
Static type checking] - Cannot find matching method TestScript0#length()
在这种情况下,您可以使用 @DelegatesTo 注解的 type 成员将 T 引用为类型令牌
class Mapper<T,U> {
final T value
Mapper(T value) { this.value = value }
U map(@DelegatesTo(type="T") Closure<U> producer) { (1)
producer.delegate = value
producer()
}
}| 1 | @DelegatesTo 注解引用了方法签名中未找到的泛型类型 |
请注意,您不仅限于泛型类型标记。type 成员可用于表示复杂类型,例如 List<T> 或 Map<T,List<U>>。您应该将其作为最后手段使用的原因是,类型只在类型检查器发现 @DelegatesTo 的用法时检查,而不是在注解方法本身编译时检查。这意味着类型安全只在调用站点得到保证。此外,编译会变慢(尽管在大多数情况下可能不明显)。
6. 编译定制器
6.1. 简介
无论您是使用 groovyc 编译类,还是使用 GroovyShell 执行脚本,在底层,都会使用一个编译器配置。此配置包含源编码或类路径等信息,但它也可以用于执行更多操作,例如默认添加导入、透明地应用 AST 转换或禁用全局 AST 转换。
编译定制器的目标是使这些常见任务易于实现。为此,CompilerConfiguration 类是入口点。通用模式将始终基于以下代码
import org.codehaus.groovy.control.CompilerConfiguration
// create a configuration
def config = new CompilerConfiguration()
// tweak the configuration
config.addCompilationCustomizers(...)
// run your script
def shell = new GroovyShell(config)
shell.evaluate(script)编译定制器必须扩展 org.codehaus.groovy.control.customizers.CompilationCustomizer 类。定制器工作
-
在特定的编译阶段
-
在每个正在编译的类节点上
您可以实现自己的编译定制器,但 Groovy 包含一些最常见的操作。
6.2. 导入定制器
使用此编译定制器,您的代码将透明地添加导入。这对于实现 DSL 的脚本特别有用,您希望避免用户编写导入。导入定制器将允许您添加 Groovy 语言允许的所有导入变体,即
-
类导入,可选别名
-
星型导入
-
静态导入,可选别名
-
静态星型导入
import org.codehaus.groovy.control.customizers.ImportCustomizer
def icz = new ImportCustomizer()
// "normal" import
icz.addImports('java.util.concurrent.atomic.AtomicInteger', 'java.util.concurrent.ConcurrentHashMap')
// "aliases" import
icz.addImport('CHM', 'java.util.concurrent.ConcurrentHashMap')
// "static" import
icz.addStaticImport('java.lang.Math', 'PI') // import static java.lang.Math.PI
// "aliased static" import
icz.addStaticImport('pi', 'java.lang.Math', 'PI') // import static java.lang.Math.PI as pi
// "star" import
icz.addStarImports 'java.util.concurrent' // import java.util.concurrent.*
// "static star" import
icz.addStaticStars 'java.lang.Math' // import static java.lang.Math.*所有快捷方式的详细描述可以在 org.codehaus.groovy.control.customizers.ImportCustomizer 中找到
6.3. AST 转换定制器
AST 转换定制器旨在透明地应用 AST 转换。与全局 AST 转换不同,全局 AST 转换只要在类路径上找到转换就会应用于每个正在编译的类(这有增加编译时间或因转换应用不当而产生副作用等缺点),定制器将允许您有选择地仅对特定脚本或类应用转换。
例如,假设您想在脚本中使用 @Log。问题是 @Log 通常应用于类节点,而脚本(根据定义)不需要类节点。但从实现角度来看,脚本是类,只是您不能用 @Log 注解这个隐式类节点。使用 AST 定制器,您有一个解决方法
import org.codehaus.groovy.control.customizers.ASTTransformationCustomizer
import groovy.util.logging.Log
def acz = new ASTTransformationCustomizer(Log)
config.addCompilationCustomizers(acz)就这样!在内部,@Log AST 转换应用于编译单元中的每个类节点。这意味着它将应用于脚本,以及在脚本中定义的类。
如果您使用的 AST 转换接受参数,则也可以在构造函数中使用参数
def acz = new ASTTransformationCustomizer(Log, value: 'LOGGER')
// use name 'LOGGER' instead of the default 'log'
config.addCompilationCustomizers(acz)由于 AST 转换定制器处理对象而不是 AST 节点,因此并非所有值都可以转换为 AST 转换参数。例如,基本类型被转换为 ConstantExpression(即 LOGGER 被转换为 new ConstantExpression('LOGGER')),但如果您的 AST 转换接受闭包作为参数,则必须为其提供 ClosureExpression,如下例所示
def configuration = new CompilerConfiguration()
def expression = new AstBuilder().buildFromCode(CompilePhase.CONVERSION) { -> true }.expression[0]
def customizer = new ASTTransformationCustomizer(ConditionalInterrupt, value: expression, thrown: SecurityException)
configuration.addCompilationCustomizers(customizer)
def shell = new GroovyShell(configuration)
shouldFail(SecurityException) {
shell.evaluate("""
// equivalent to adding @ConditionalInterrupt(value={true}, thrown: SecurityException)
class MyClass {
void doIt() { }
}
new MyClass().doIt()
""")
}6.4. 安全 AST 定制器
此定制器将允许 DSL 开发人员限制语言的**语法**,例如,防止用户使用特定的构造。它仅在这一方面是“安全”的,即限制 DSL 中允许的构造。它**不能**替代可能还需要作为整体安全正交方面的安全管理器。它存在的唯一原因是限制语言的表达能力。此定制器只在 AST(抽象语法树)级别工作,不在运行时工作!乍一看可能很奇怪,但如果将 Groovy 视为构建 DSL 的平台,它就更有意义了。您可能不希望用户拥有完整的语言。在下面的示例中,我们将使用一个只允许算术运算的语言示例来演示它,但此定制器允许您
-
允许/禁止创建闭包
-
允许/禁止导入
-
允许/禁止包定义
-
允许/禁止方法定义
-
限制方法调用的接收者
-
限制用户可以使用的 AST 表达式类型
-
限制用户可以使用的令牌(语法方面)
-
限制代码中可以使用常量的类型
对于所有这些功能,安全 AST 定制器使用允许列表(允许的元素列表)**或**禁止列表(不允许的元素列表)。对于每种类型的功能(导入、令牌等),您可以选择使用允许列表或禁止列表,但您可以混合使用不同功能的禁止/允许列表。通常,您会选择允许列表(只允许列出的构造并禁止所有其他构造)。
import org.codehaus.groovy.control.customizers.SecureASTCustomizer
import static org.codehaus.groovy.syntax.Types.* (1)
def scz = new SecureASTCustomizer()
scz.with {
closuresAllowed = false // user will not be able to write closures
methodDefinitionAllowed = false // user will not be able to define methods
allowedImports = [] // empty allowed list means imports are disallowed
allowedStaticImports = [] // same for static imports
allowedStaticStarImports = ['java.lang.Math'] // only java.lang.Math is allowed
// the list of tokens the user can find
// constants are defined in org.codehaus.groovy.syntax.Types
allowedTokens = [ (1)
PLUS,
MINUS,
MULTIPLY,
DIVIDE,
MOD,
POWER,
PLUS_PLUS,
MINUS_MINUS,
COMPARE_EQUAL,
COMPARE_NOT_EQUAL,
COMPARE_LESS_THAN,
COMPARE_LESS_THAN_EQUAL,
COMPARE_GREATER_THAN,
COMPARE_GREATER_THAN_EQUAL,
].asImmutable()
// limit the types of constants that a user can define to number types only
allowedConstantTypesClasses = [ (2)
Integer,
Float,
Long,
Double,
BigDecimal,
Integer.TYPE,
Long.TYPE,
Float.TYPE,
Double.TYPE
].asImmutable()
// method calls are only allowed if the receiver is of one of those types
// be careful, it's not a runtime type!
allowedReceiversClasses = [ (2)
Math,
Integer,
Float,
Double,
Long,
BigDecimal
].asImmutable()
}| 1 | 用于来自 org.codehaus.groovy.syntax.Types 的令牌类型 |
| 2 | 您可以在这里使用类字面量 |
如果安全 AST 定制器开箱即用的功能不足以满足您的需求,在创建自己的编译定制器之前,您可能会对 AST 定制器支持的表达式和语句检查器感兴趣。基本上,它允许您在 AST 树上,在表达式(表达式检查器)或语句(语句检查器)上添加自定义检查。为此,您必须实现 org.codehaus.groovy.control.customizers.SecureASTCustomizer.StatementChecker 或 org.codehaus.groovy.control.customizers.SecureASTCustomizer.ExpressionChecker。
这些接口定义了一个名为 isAuthorized 的单一方法,返回布尔值,并接受 Statement(或 Expression)作为参数。它允许您对表达式或语句执行复杂逻辑,以判断用户是否被允许这样做。
例如,定制器中没有预定义的配置标志可以阻止人们使用属性表达式。使用自定义检查器,这很简单
def scz = new SecureASTCustomizer()
def checker = { expr ->
!(expr instanceof AttributeExpression)
} as SecureASTCustomizer.ExpressionChecker
scz.addExpressionCheckers(checker)然后我们可以通过评估一个简单的脚本来确保它有效
new GroovyShell(config).evaluate '''
class A {
int val
}
def a = new A(val: 123)
a.@val (1)
'''| 1 | 将编译失败 |
6.5. 源感知定制器
此定制器可用作其他定制器上的过滤器。在这种情况下,过滤器是 org.codehaus.groovy.control.SourceUnit。为此,源感知定制器将另一个定制器作为委托,并且只有当源单元上的谓词匹配时,它才会应用该委托的定制。
SourceUnit 允许您访问多种内容,特别是正在编译的文件(当然,如果从文件编译)。它使您能够根据文件名执行操作,例如。以下是创建源感知定制器的方法
import org.codehaus.groovy.control.customizers.SourceAwareCustomizer
import org.codehaus.groovy.control.customizers.ImportCustomizer
def delegate = new ImportCustomizer()
def sac = new SourceAwareCustomizer(delegate)然后您可以在源感知定制器上使用谓词
// the customizer will only be applied to classes contained in a file name ending with 'Bean'
sac.baseNameValidator = { baseName ->
baseName.endsWith 'Bean'
}
// the customizer will only be applied to files which extension is '.spec'
sac.extensionValidator = { ext -> ext == 'spec' }
// source unit validation
// allow compilation only if the file contains at most 1 class
sac.sourceUnitValidator = { SourceUnit sourceUnit -> sourceUnit.AST.classes.size() == 1 }
// class validation
// the customizer will only be applied to classes ending with 'Bean'
sac.classValidator = { ClassNode cn -> cn.endsWith('Bean') }6.6. 定制器构建器
如果您在 Groovy 代码中使用编译定制器(如上例所示),那么您可以使用替代语法来自定义编译。构建器(org.codehaus.groovy.control.customizers.builder.CompilerCustomizationBuilder)通过分层 DSL 简化了定制器的创建。
import org.codehaus.groovy.control.CompilerConfiguration
import static org.codehaus.groovy.control.customizers.builder.CompilerCustomizationBuilder.withConfig (1)
def conf = new CompilerConfiguration()
withConfig(conf) {
// ... (2)
}| 1 | 构建器方法的静态导入 |
| 2 | 配置在此处 |
上面的代码示例展示了如何使用构建器。一个静态方法 withConfig 接受一个与构建器代码对应的闭包,并自动将编译定制器注册到配置中。发行版中可用的每个编译定制器都可以通过这种方式进行配置
6.6.1. 导入定制器
withConfig(configuration) {
imports { // imports customizer
normal 'my.package.MyClass' // a normal import
alias 'AI', 'java.util.concurrent.atomic.AtomicInteger' // an aliased import
star 'java.util.concurrent' // star imports
staticMember 'java.lang.Math', 'PI' // static import
staticMember 'pi', 'java.lang.Math', 'PI' // aliased static import
}
}6.6.2. AST 转换定制器
withConfig(conf) {
ast(Log) (1)
}
withConfig(conf) {
ast(Log, value: 'LOGGER') (2)
}| 1 | 透明应用 @Log |
| 2 | 应用 @Log,但使用不同的记录器名称 |
6.6.3. 安全 AST 定制器
withConfig(conf) {
secureAst {
closuresAllowed = false
methodDefinitionAllowed = false
}
}6.6.4. 源感知定制器
withConfig(configuration){
source(extension: 'sgroovy') {
ast(CompileStatic) (1)
}
}
withConfig(configuration){
source(extensions: ['sgroovy','sg']) {
ast(CompileStatic) (2)
}
}
withConfig(configuration) {
source(extensionValidator: { it.name in ['sgroovy','sg']}) {
ast(CompileStatic) (2)
}
}
withConfig(configuration) {
source(basename: 'foo') {
ast(CompileStatic) (3)
}
}
withConfig(configuration) {
source(basenames: ['foo', 'bar']) {
ast(CompileStatic) (4)
}
}
withConfig(configuration) {
source(basenameValidator: { it in ['foo', 'bar'] }) {
ast(CompileStatic) (4)
}
}
withConfig(configuration) {
source(unitValidator: { unit -> !unit.AST.classes.any { it.name == 'Baz' } }) {
ast(CompileStatic) (5)
}
}| 1 | 对 .sgroovy 文件应用 CompileStatic AST 注解 |
| 2 | 对 .sgroovy 或 .sg 文件应用 CompileStatic AST 注解 |
| 3 | 对名为 'foo' 的文件应用 CompileStatic AST 注解 |
| 4 | 对名为 'foo' 或 'bar' 的文件应用 CompileStatic AST 注解 |
| 5 | 对不包含名为 'Baz' 的类的文件应用 CompileStatic AST 注解 |
6.6.5. 内联定制器
内联定制器允许您直接编写编译定制器,而无需为其创建类。
withConfig(configuration) {
inline(phase:'CONVERSION') { source, context, classNode -> (1)
println "visiting $classNode" (2)
}
}| 1 | 定义一个内联定制器,它将在 CONVERSION 阶段执行 |
| 2 | 打印正在编译的类节点的名称 |
6.7. configscript 命令行参数
到目前为止,我们已经描述了如何使用 CompilationConfiguration 类来自定义编译,但这只有在您嵌入 Groovy 并创建自己的 CompilerConfiguration 实例(然后用它创建 GroovyShell、GroovyScriptEngine 等)时才可能。
如果您希望将其应用于您使用普通 Groovy 编译器(例如 groovyc、ant 或 gradle)编译的类,可以使用一个名为 configscript 的命令行参数,它接受一个 Groovy 配置文件作为参数。
此脚本使您可以在文件编译**之前**访问 CompilerConfiguration 实例(在配置文件中公开为名为 configuration 的变量),以便您可以对其进行调整。
它还透明地集成了上面的编译器配置构建器。例如,让我们看看如何默认激活所有类的静态编译。
6.7.1. Configscript 示例:默认静态编译
通常,Groovy 中的类是使用动态运行时编译的。您可以通过在任何类上放置名为 @CompileStatic 的注解来激活静态编译。有些人希望默认激活此模式,即不必注解(可能很多)类。使用 configscript 可以实现这一点。首先,您需要在 src/conf 中创建一个名为 config.groovy 的文件,其内容如下
withConfig(configuration) { (1)
ast(groovy.transform.CompileStatic)
}| 1 | configuration 引用一个 CompilerConfiguration 实例 |
这实际上就是您所需要的一切。您不必导入构建器,它会自动在脚本中公开。然后,使用以下命令行编译您的文件
groovyc -configscript src/conf/config.groovy src/main/groovy/MyClass.groovy
我们强烈建议您将配置文件与类分开,这就是我们建议使用上述 src/main 和 src/conf 目录的原因。
6.7.2. Configscript 示例:设置系统属性
在配置文件中,您还可以设置系统属性,例如
System.setProperty('spock.iKnowWhatImDoing.disableGroovyVersionCheck', 'true')如果您有许多系统属性需要设置,那么使用配置文件将减少使用长命令行或适当定义的环境变量来设置大量系统属性的需要。您还可以通过简单地共享配置文件来共享所有设置。
6.8. AST 转换
如果
-
运行时元编程不允许您实现所需功能
-
您需要提高 DSL 的执行性能
-
您想利用与 Groovy 相同的语法但具有不同的语义
-
您想改进对 DSL 中类型检查的支持
那么 AST 转换就是您的选择。与到目前为止使用的技术不同,AST 转换旨在在代码编译为字节码之前更改或生成代码。AST 转换能够例如在编译时添加新方法,或者根据您的需要完全更改方法的主体。它们是非常强大的工具,但编写起来并不容易。有关 AST 转换的更多信息,请参阅本手册的编译时元编程部分。
7. 自定义类型检查扩展
在某些情况下,尽快向用户提供有关错误代码的反馈可能很有趣,也就是说,在 DSL 脚本编译时,而不是等待脚本执行。但是,这对于动态代码通常是不可能的。Groovy 实际上为这个已知问题提供了一个实用的解决方案,称为类型检查扩展。
8. 构建器
许多任务都需要构建事物,而构建器模式是开发人员用来简化构建事物的一种技术,特别是构建具有分层性质的结构。这种模式非常普遍,以至于 Groovy 提供了特殊的内置支持。首先,有许多内置构建器。其次,有一些类可以更轻松地编写自己的构建器。
8.1. 现有构建器
Groovy 附带了许多内置构建器。让我们看看其中的一些。
8.1.3. SaxBuilder
一个用于生成 简单 XML API (SAX) 事件的构建器。
如果您有以下 SAX 处理器
class LogHandler extends org.xml.sax.helpers.DefaultHandler {
String log = ''
void startElement(String uri, String localName, String qName, org.xml.sax.Attributes attributes) {
log += "Start Element: $localName, "
}
void endElement(String uri, String localName, String qName) {
log += "End Element: $localName, "
}
}您可以使用 SaxBuilder 为处理器生成 SAX 事件,如下所示
def handler = new LogHandler()
def builder = new groovy.xml.SAXBuilder(handler)
builder.root() {
helloWorld()
}然后检查一切是否按预期工作
assert handler.log == 'Start Element: root, Start Element: helloWorld, End Element: helloWorld, End Element: root, '8.1.4. StaxBuilder
一个与 用于 XML 的流式 API (StAX) 处理器配合使用的 Groovy 构建器。
这是一个使用 Java 的 StAX 实现生成 XML 的简单示例
def factory = javax.xml.stream.XMLOutputFactory.newInstance()
def writer = new StringWriter()
def builder = new groovy.xml.StaxBuilder(factory.createXMLStreamWriter(writer))
builder.root(attribute:1) {
elem1('hello')
elem2('world')
}
assert writer.toString() == '<?xml version="1.0" ?><root attribute="1"><elem1>hello</elem1><elem2>world</elem2></root>'可以使用外部库,例如 Jettison,如下所示
@Grab('org.codehaus.jettison:jettison:1.3.3')
@GrabExclude('stax:stax-api') // part of Java 6 and later
import org.codehaus.jettison.mapped.*
def writer = new StringWriter()
def mappedWriter = new MappedXMLStreamWriter(new MappedNamespaceConvention(), writer)
def builder = new groovy.xml.StaxBuilder(mappedWriter)
builder.root(attribute:1) {
elem1('hello')
elem2('world')
}
assert writer.toString() == '{"root":{"@attribute":"1","elem1":"hello","elem2":"world"}}'8.1.5. DOMBuilder
一个用于将 HTML、XHTML 和 XML 解析为 W3C DOM 树的构建器。
例如这个 XML String
String recordsXML = '''
<records>
<car name='HSV Maloo' make='Holden' year='2006'>
<country>Australia</country>
<record type='speed'>Production Pickup Truck with speed of 271kph</record>
</car>
<car name='P50' make='Peel' year='1962'>
<country>Isle of Man</country>
<record type='size'>Smallest Street-Legal Car at 99cm wide and 59 kg in weight</record>
</car>
<car name='Royale' make='Bugatti' year='1931'>
<country>France</country>
<record type='price'>Most Valuable Car at $15 million</record>
</car>
</records>'''可以使用 DOMBuilder 解析成 DOM 树,如下所示
def reader = new StringReader(recordsXML)
def doc = groovy.xml.DOMBuilder.parse(reader)然后进一步处理,例如通过使用 DOMCategory
def records = doc.documentElement
use(groovy.xml.dom.DOMCategory) {
assert records.car.size() == 3
}8.1.6. NodeBuilder
NodeBuilder 用于创建 groovy.util.Node 对象的嵌套树,用于处理任意数据。要创建简单的用户列表,您可以使用 NodeBuilder,如下所示
def nodeBuilder = new NodeBuilder()
def userlist = nodeBuilder.userlist {
user(id: '1', firstname: 'John', lastname: 'Smith') {
address(type: 'home', street: '1 Main St.', city: 'Springfield', state: 'MA', zip: '12345')
address(type: 'work', street: '2 South St.', city: 'Boston', state: 'MA', zip: '98765')
}
user(id: '2', firstname: 'Alice', lastname: 'Doe')
}现在您可以进一步处理数据,例如通过使用 GPath 表达式
assert userlist.user.@firstname.join(', ') == 'John, Alice'
assert userlist.user.find { it.@lastname == 'Smith' }.address.size() == 28.1.7. JsonBuilder
Groovy 的 JsonBuilder 使创建 Json 变得容易。例如,要创建此 Json 字符串
String carRecords = '''
{
"records": {
"car": {
"name": "HSV Maloo",
"make": "Holden",
"year": 2006,
"country": "Australia",
"record": {
"type": "speed",
"description": "production pickup truck with speed of 271kph"
}
}
}
}
'''您可以使用 JsonBuilder,如下所示
JsonBuilder builder = new JsonBuilder()
builder.records {
car {
name 'HSV Maloo'
make 'Holden'
year 2006
country 'Australia'
record {
type 'speed'
description 'production pickup truck with speed of 271kph'
}
}
}
String json = JsonOutput.prettyPrint(builder.toString())我们使用 JsonUnit 来检查构建器是否产生了预期的结果
JsonAssert.assertJsonEquals(json, carRecords)如果需要自定义生成的输出,可以在创建 JsonBuilder 时传入 JsonGenerator 实例
import groovy.json.*
def generator = new JsonGenerator.Options()
.excludeNulls()
.excludeFieldsByName('make', 'country', 'record')
.excludeFieldsByType(Number)
.addConverter(URL) { url -> "https://groovy-lang.cn" }
.build()
JsonBuilder builder = new JsonBuilder(generator)
builder.records {
car {
name 'HSV Maloo'
make 'Holden'
year 2006
country 'Australia'
homepage new URL('http://example.org')
record {
type 'speed'
description 'production pickup truck with speed of 271kph'
}
}
}
assert builder.toString() == '{"records":{"car":{"name":"HSV Maloo","homepage":"https://groovy-lang.cn"}}}'8.1.8. StreamingJsonBuilder
与 JsonBuilder 不同,后者在内存中创建数据结构,这在您希望在输出之前以编程方式更改结构的情况下很方便,StreamingJsonBuilder 直接流式传输到写入器,而无需任何中间内存数据结构。如果您不需要修改结构并希望采用更节省内存的方法,请使用 StreamingJsonBuilder。
StreamingJsonBuilder 的用法与 JsonBuilder 类似。为了创建此 Json 字符串
String carRecords = """
{
"records": {
"car": {
"name": "HSV Maloo",
"make": "Holden",
"year": 2006,
"country": "Australia",
"record": {
"type": "speed",
"description": "production pickup truck with speed of 271kph"
}
}
}
}
"""您可以使用 StreamingJsonBuilder,如下所示
StringWriter writer = new StringWriter()
StreamingJsonBuilder builder = new StreamingJsonBuilder(writer)
builder.records {
car {
name 'HSV Maloo'
make 'Holden'
year 2006
country 'Australia'
record {
type 'speed'
description 'production pickup truck with speed of 271kph'
}
}
}
String json = JsonOutput.prettyPrint(writer.toString())我们使用 JsonUnit 来检查预期结果
JsonAssert.assertJsonEquals(json, carRecords)如果需要自定义生成的输出,可以在创建 StreamingJsonBuilder 时传入 JsonGenerator 实例
def generator = new JsonGenerator.Options()
.excludeNulls()
.excludeFieldsByName('make', 'country', 'record')
.excludeFieldsByType(Number)
.addConverter(URL) { url -> "https://groovy-lang.cn" }
.build()
StringWriter writer = new StringWriter()
StreamingJsonBuilder builder = new StreamingJsonBuilder(writer, generator)
builder.records {
car {
name 'HSV Maloo'
make 'Holden'
year 2006
country 'Australia'
homepage new URL('http://example.org')
record {
type 'speed'
description 'production pickup truck with speed of 271kph'
}
}
}
assert writer.toString() == '{"records":{"car":{"name":"HSV Maloo","homepage":"https://groovy-lang.cn"}}}'8.1.9. SwingBuilder
SwingBuilder 允许您以声明和简洁的方式创建功能齐全的 Swing GUI。它通过利用 Groovy 中常见的惯用语(构建器)来实现这一点。构建器负责为您创建复杂对象(例如实例化子对象、调用 Swing 方法并将这些子对象附加到其父对象)的繁琐工作。因此,您的代码更具可读性和可维护性,同时仍允许您访问各种 Swing 组件。
下面是一个使用 SwingBuilder 的简单示例
import groovy.swing.SwingBuilder
import java.awt.BorderLayout as BL
count = 0
new SwingBuilder().edt {
frame(title: 'Frame', size: [250, 75], show: true) {
borderLayout()
textlabel = label(text: 'Click the button!', constraints: BL.NORTH)
button(text:'Click Me',
actionPerformed: {count++; textlabel.text = "Clicked ${count} time(s)."; println "clicked"}, constraints:BL.SOUTH)
}
}它将如下所示

这种组件层次结构通常是通过一系列重复的实例化、设置器,最后将此子组件附加到其相应的父组件来创建的。然而,使用 SwingBuilder 允许您以其本机形式定义此层次结构,这使得界面设计仅通过阅读代码即可理解。
这里展示的灵活性是通过利用 Groovy 中内置的许多编程功能实现的,例如闭包、隐式构造函数调用、导入别名和字符串插值。当然,不必完全理解这些功能才能使用 SwingBuilder;正如您从上面的代码中看到的,它们的用法是直观的。
这是一个稍微复杂一点的示例,其中包含一个通过闭包重用 SwingBuilder 代码的示例。
import groovy.swing.SwingBuilder
import javax.swing.*
import java.awt.*
def swing = new SwingBuilder()
def sharedPanel = {
swing.panel() {
label("Shared Panel")
}
}
count = 0
swing.edt {
frame(title: 'Frame', defaultCloseOperation: JFrame.EXIT_ON_CLOSE, pack: true, show: true) {
vbox {
textlabel = label('Click the button!')
button(
text: 'Click Me',
actionPerformed: {
count++
textlabel.text = "Clicked ${count} time(s)."
println "Clicked!"
}
)
widget(sharedPanel())
widget(sharedPanel())
}
}
}这是另一个依赖于可观察 bean 和绑定的变体
import groovy.swing.SwingBuilder
import groovy.beans.Bindable
class MyModel {
@Bindable int count = 0
}
def model = new MyModel()
new SwingBuilder().edt {
frame(title: 'Java Frame', size: [100, 100], locationRelativeTo: null, show: true) {
gridLayout(cols: 1, rows: 2)
label(text: bind(source: model, sourceProperty: 'count', converter: { v -> v? "Clicked $v times": ''}))
button('Click me!', actionPerformed: { model.count++ })
}
}@Bindable 是核心 AST 转换之一。它生成所有必需的样板代码,将一个简单的 bean 转换为可观察的 bean。bind() 节点创建适当的 PropertyChangeListeners,这些监听器将在触发 PropertyChangeEvent 时更新感兴趣的方。
8.1.10. AntBuilder
这里我们描述 AntBuilder,它允许您用 Groovy 而不是 XML 编写 Ant 构建脚本。您可能还有兴趣使用 Groovy Ant 任务从 Ant 中使用 Groovy。 |
尽管 Apache Ant 主要是一个构建工具,但它是一个非常实用的文件操作工具,包括 zip 文件、复制、资源处理等等。但是,如果您曾经使用过 build.xml 文件或某些 Jelly 脚本,并发现自己受限于所有那些尖括号,或者觉得使用 XML 作为脚本语言有点奇怪,并且想要更简洁、更直接的东西,那么也许使用 Groovy 进行 Ant 脚本编写就是您所追求的。
Groovy 有一个名为 AntBuilder 的辅助类,它使得 Ant 任务的脚本编写变得非常容易;允许使用真正的脚本语言进行编程构造(变量、方法、循环、逻辑分支、类等)。它仍然看起来像 Ant XML 的简洁版本,没有所有那些尖括号;尽管您可以在脚本中混合使用此标记。Ant 本身是一个 jar 文件集合。通过将它们添加到您的类路径中,您可以轻松地在 Groovy 中原样使用它们。我们相信使用 AntBuilder 会带来更简洁易懂的语法。
AntBuilder 使用我们在 Groovy 中习惯的便捷构建器符号直接公开 Ant 任务。这是最基本的示例,即在标准输出上打印消息
def ant = new groovy.ant.AntBuilder() (1)
ant.echo('hello from Ant!') (2)| 1 | 创建 AntBuilder 实例 |
| 2 | 执行 echo 任务,消息作为参数 |
假设您需要创建一个 ZIP 文件。它可以像这样简单
def ant = new AntBuilder()
ant.zip(destfile: 'sources.zip', basedir: 'src')在下一个示例中,我们演示了如何使用 AntBuilder 在 Groovy 中直接使用经典的 Ant 模式复制文件列表
// let's just call one task
ant.echo("hello")
// here is an example of a block of Ant inside GroovyMarkup
ant.sequential {
echo("inside sequential")
def myDir = "build/AntTest/"
mkdir(dir: myDir)
copy(todir: myDir) {
fileset(dir: "src/test") {
include(name: "**/*.groovy")
}
}
echo("done")
}
// now let's do some normal Groovy again
def file = new File(ant.project.baseDir,"build/AntTest/some/pkg/MyTest.groovy")
assert file.exists()另一个例子是遍历匹配特定模式的文件列表
// let's create a scanner of filesets
def scanner = ant.fileScanner {
fileset(dir:"src/test") {
include(name:"**/My*.groovy")
}
}
// now let's iterate over
def found = false
for (f in scanner) {
println("Found file $f")
found = true
assert f instanceof File
assert f.name.endsWith(".groovy")
}
assert found或执行 JUnit 测试
ant.junit {
classpath { pathelement(path: '.') }
test(name:'some.pkg.MyTest')
}我们甚至可以更进一步,直接从 Groovy 编译和执行 Java 文件
ant.echo(file:'Temp.java', '''
class Temp {
public static void main(String[] args) {
System.out.println("Hello");
}
}
''')
ant.javac(srcdir:'.', includes:'Temp.java', fork:'true')
ant.java(classpath:'.', classname:'Temp', fork:'true')
ant.echo('Done')8.1.11. CliBuilder
CliBuilder 提供了一种紧凑的方式来指定命令行应用程序的可用选项,然后根据该规范自动解析应用程序的命令行参数。按照惯例,命令行参数分为选项参数和作为应用程序参数传递的任何剩余参数。通常,可能会支持几种类型的选项,例如 -V 或 --tabsize=4。CliBuilder 解除了开发大量代码进行命令行处理的负担。相反,它支持一种声明式的方法来声明您的选项,然后提供一个单独的调用来解析命令行参数,并提供一种简单的机制来查询选项(您可以将其视为选项的简单模型)。
尽管您创建的每个命令行的细节可能大相径庭,但每次都遵循相同的主要步骤。首先,创建 CliBuilder 实例。然后,定义允许的命令行选项。这可以使用动态 API样式或注解样式完成。然后根据选项规范解析命令行参数,从而生成一个选项集合,然后对这些选项进行查询。
这是一个简单的 Greeter.groovy 脚本,说明了用法
// import of CliBuilder not shown (1)
// specify parameters
def cli = new CliBuilder(usage: 'groovy Greeter [option]') (2)
cli.a(longOpt: 'audience', args: 1, 'greeting audience') (3)
cli.h(longOpt: 'help', 'display usage') (4)
// parse and process parameters
def options = cli.parse(args) (5)
if (options.h) cli.usage() (6)
else println "Hello ${options.a ? options.a : 'World'}" (7)| 1 | 早期版本的 Groovy 在 groovy.util 包中有一个 CliBuilder,并且不需要导入。在 Groovy 2.5 中,这种方法被弃用:应用程序应该选择 groovy.cli.picocli 或 groovy.cli.commons 版本。Groovy 2.5 中的 groovy.util 版本指向 commons-cli 版本以实现向后兼容,但已在 Groovy 3.0 中删除。 |
| 2 | 定义一个新的 CliBuilder 实例,指定一个可选的用法字符串 |
| 3 | 指定一个接受单个参数的可选长变体 --audience 的 -a 选项 |
| 4 | 指定一个不带参数的可选长变体 --help 的 -h 选项 |
| 5 | 解析提供给脚本的命令行参数 |
| 6 | 如果找到 h 选项,则显示用法消息 |
| 7 | 显示标准问候语,如果找到 a 选项,则显示自定义问候语 |
运行此脚本,不带命令行参数,即
> groovy Greeter结果如下
Hello World
运行此脚本,-h 作为唯一的命令行参数,即
> groovy Greeter -h结果如下
usage: groovy Greeter [option] -a,--audience <arg> greeting audience -h,--help display usage
运行此脚本,--audience Groovologist 作为命令行参数,即
> groovy Greeter --audience Groovologist结果如下
Hello Groovologist
在上面的示例中创建 CliBuilder 实例时,我们在构造函数调用中设置了可选的 usage 属性。这遵循 Groovy 在构造过程中设置实例附加属性的正常能力。还有许多其他属性可以设置,例如 header 和 footer。有关可用属性的完整集合,请参阅 groovy.util.CliBuilder 类可用的属性。
定义允许的命令行选项时,必须同时提供短名称(例如,前面所示的 help 选项的“h”)和简短描述(例如,help 选项的“显示用法”)。在我们的示例中,我们还设置了一些附加属性,例如 longOpt 和 args。指定允许的命令行选项时支持以下附加属性
| 名称 | 描述 | 类型 |
|---|---|---|
argName |
此选项的参数名称,用于输出 |
|
longOpt |
选项的长表示或长名称 |
|
args |
参数值的数量 |
|
optionalArg |
参数值是否可选 |
|
required |
选项是否强制 |
|
type |
此选项的类型 |
|
valueSeparator |
值分隔符字符 |
|
defaultValue |
默认值 |
|
convert |
将传入的 String 转换为所需类型 |
|
(1) 稍后详情
(2) 单字符字符串在 Groovy 的特殊情况下被强制转换为字符
如果您的选项只有一个 longOpt 变体,则可以使用特殊的短名称 '_' 来指定该选项,例如:cli._(longOpt: 'verbose', 'enable verbose logging')。其他一些命名参数应该相当一目了然,而另一些则需要更多解释。但在进一步解释之前,让我们看看使用注解使用 CliBuilder 的方法。
使用注解和接口
除了进行一系列方法调用(尽管以非常声明式的迷你 DSL 形式)来指定允许的选项之外,您还可以提供允许选项的接口规范,其中注解用于指示和提供这些选项的详细信息以及如何处理未处理的参数。使用了两个注解:groovy.cli.Option 和 groovy.cli.Unparsed。
以下是此类规范的定义方式
interface GreeterI {
@Option(shortName='h', description='display usage') Boolean help() (1)
@Option(shortName='a', description='greeting audience') String audience() (2)
@Unparsed(description = "positional parameters") List remaining() (3)
}| 1 | 指定一个使用 -h 或 --help 设置的布尔选项 |
| 2 | 指定一个使用 -a 或 --audience 设置的字符串选项 |
| 3 | 指定任何剩余参数的存储位置 |
请注意长名称是如何从接口方法名称自动确定的。您可以使用 longName 注解属性来覆盖此行为并指定自定义长名称,或者使用 '_' 的 longName 来指示不提供长名称。在这种情况下,您需要指定一个短名称。
以下是您如何使用接口规范
// import CliBuilder not shown
def cli = new CliBuilder(usage: 'groovy Greeter') (1)
def argz = '--audience Groovologist'.split()
def options = cli.parseFromSpec(GreeterI, argz) (2)
assert options.audience() == 'Groovologist' (3)
argz = '-h Some Other Args'.split()
options = cli.parseFromSpec(GreeterI, argz) (4)
assert options.help()
assert options.remaining() == ['Some', 'Other', 'Args'] (5)| 1 | 像以前一样创建带可选属性的 CliBuilder 实例 |
| 2 | 使用接口规范解析参数 |
| 3 | 使用接口中的方法查询选项 |
| 4 | 解析一组不同的参数 |
| 5 | 查询剩余参数 |
调用 parseFromSpec 时,CliBuilder 会自动创建一个实现接口的实例并填充它。您只需调用接口方法即可查询选项值。
使用注解和实例
或者,您可能已经有一个包含选项信息的领域类。您只需注解该类中的属性或 setter,即可使 CliBuilder 适当地填充您的领域对象。每个注解都通过注解属性描述了该选项的属性,并指示 CliBuilder 将用于在您的领域对象中填充该选项的 setter。
以下是此类规范的定义方式
class GreeterC {
@Option(shortName='h', description='display usage')
Boolean help (1)
private String audience
@Option(shortName='a', description='greeting audience')
void setAudience(String audience) { (2)
this.audience = audience
}
String getAudience() { audience }
@Unparsed(description = "positional parameters")
List remaining (3)
}| 1 | 指示布尔属性是选项 |
| 2 | 指示字符串属性(带显式 setter)是选项 |
| 3 | 指定任何剩余参数的存储位置 |
以下是您如何使用此规范
// import CliBuilder not shown
def cli = new CliBuilder(usage: 'groovy Greeter [option]') (1)
def options = new GreeterC() (2)
def argz = '--audience Groovologist foo'.split()
cli.parseFromInstance(options, argz) (3)
assert options.audience == 'Groovologist' (4)
assert options.remaining == ['foo'] (5)| 1 | 像以前一样创建带可选参数的 CliBuilder 实例 |
| 2 | 创建 CliBuilder 要填充的实例 |
| 3 | 解析参数,填充提供的实例 |
| 4 | 查询字符串选项属性 |
| 5 | 查询剩余参数属性 |
调用 parseFromInstance 时,CliBuilder 会自动填充您的实例。您只需查询实例属性(或您在领域对象中提供的任何访问器方法)即可访问选项值。
使用注解和脚本
最后,还有两个额外的方便注解别名专门用于脚本。它们只是结合了前面提到的注解和 groovy.transform.Field。这些注解的 groovydoc 揭示了详细信息:groovy.cli.OptionField 和 groovy.cli.UnparsedField。
这是一个使用这些注解的自包含脚本示例,该脚本将使用与前面实例示例中所示的相同参数调用
// import CliBuilder not shown
import groovy.cli.OptionField
import groovy.cli.UnparsedField
@OptionField String audience
@OptionField Boolean help
@UnparsedField List remaining
new CliBuilder().parseFromInstance(this, args)
assert audience == 'Groovologist'
assert remaining == ['foo']带参数的选项
我们在最初的示例中看到,有些选项充当标志,例如 Greeter -h,而另一些则接受参数,例如 Greeter --audience Groovologist。最简单的情况涉及充当标志或具有单个(可能可选)参数的选项。这是一个涉及这些情况的示例
// import CliBuilder not shown
def cli = new CliBuilder()
cli.a(args: 0, 'a arg') (1)
cli.b(args: 1, 'b arg') (2)
cli.c(args: 1, optionalArg: true, 'c arg') (3)
def options = cli.parse('-a -b foo -c bar baz'.split()) (4)
assert options.a == true
assert options.b == 'foo'
assert options.c == 'bar'
assert options.arguments() == ['baz']
options = cli.parse('-a -c -b foo bar baz'.split()) (5)
assert options.a == true
assert options.c == true
assert options.b == 'foo'
assert options.arguments() == ['bar', 'baz']| 1 | 仅作为标志的选项 - 默认;允许设置 args 为 0 但不是必需的。 |
| 2 | 恰好带一个参数的选项 |
| 3 | 带可选参数的选项;如果省略选项,则它充当标志 |
| 4 | 使用此规范的示例,其中为“c”选项提供了参数 |
| 5 | 使用此规范的示例,其中未为“c”选项提供参数;它只是一个标志 |
注意:当遇到带有可选参数的选项时,它将(某种程度上)贪婪地消耗提供给命令行参数的下一个参数。但是,如果下一个参数匹配已知的长选项或短选项(带有前导单或双连字符),则该选项将优先,例如上面示例中的 -b。
选项参数也可以使用注解样式指定。这是一个说明这种定义的接口选项规范
interface WithArgsI {
@Option boolean a()
@Option String b()
@Option(optionalArg=true) String[] c()
@Unparsed List remaining()
}以下是它的使用方法
def cli = new CliBuilder()
def options = cli.parseFromSpec(WithArgsI, '-a -b foo -c bar baz'.split())
assert options.a()
assert options.b() == 'foo'
assert options.c() == ['bar']
assert options.remaining() == ['baz']
options = cli.parseFromSpec(WithArgsI, '-a -c -b foo bar baz'.split())
assert options.a()
assert options.c() == []
assert options.b() == 'foo'
assert options.remaining() == ['bar', 'baz']此示例使用了数组类型的选项规范。我们将在稍后讨论多个参数时更详细地介绍这一点。
指定类型
命令行上的参数本质上是字符串(或者可以说可以是布尔值),但可以通过提供额外的类型信息自动转换为更丰富的类型。对于基于注解的参数定义样式,这些类型通过注解属性的字段类型或注解方法的返回类型(或 setter 方法的 setter 参数类型)提供。对于动态方法样式的参数定义,支持特殊的“type”属性,允许您指定类名。
当定义了显式类型时,命名参数 args 假定为 1(布尔类型选项除外,其中默认值为 0)。如果需要,仍然可以提供显式 args 参数。这是一个使用动态 API 参数定义样式指定类型的示例
def argz = '''-a John -b -d 21 -e 1980 -f 3.5 -g 3.14159
-h cv.txt -i DOWN and some more'''.split()
def cli = new CliBuilder()
cli.a(type: String, 'a-arg')
cli.b(type: boolean, 'b-arg')
cli.c(type: Boolean, 'c-arg')
cli.d(type: int, 'd-arg')
cli.e(type: Long, 'e-arg')
cli.f(type: Float, 'f-arg')
cli.g(type: BigDecimal, 'g-arg')
cli.h(type: File, 'h-arg')
cli.i(type: RoundingMode, 'i-arg')
def options = cli.parse(argz)
assert options.a == 'John'
assert options.b
assert !options.c
assert options.d == 21
assert options.e == 1980L
assert options.f == 3.5f
assert options.g == 3.14159
assert options.h == new File('cv.txt')
assert options.i == RoundingMode.DOWN
assert options.arguments() == ['and', 'some', 'more']支持基本类型、数字类型、文件、枚举及其数组(它们使用 org.codehaus.groovy.runtime.StringGroovyMethods#asType 转换)。
参数字符串的自定义解析
如果支持的类型不足,您可以提供一个闭包来为您处理字符串到富类型的转换。这是一个使用动态 API 样式的示例
def argz = '''-a John -b Mary -d 2016-01-01 and some more'''.split()
def cli = new CliBuilder()
def lower = { it.toLowerCase() }
cli.a(convert: lower, 'a-arg')
cli.b(convert: { it.toUpperCase() }, 'b-arg')
cli.d(convert: { Date.parse('yyyy-MM-dd', it) }, 'd-arg')
def options = cli.parse(argz)
assert options.a == 'john'
assert options.b == 'MARY'
assert options.d.format('dd-MM-yyyy') == '01-01-2016'
assert options.arguments() == ['and', 'some', 'more']或者,您可以使用注解样式,通过将转换闭包作为注解参数提供。这是一个示例规范
interface WithConvertI {
@Option(convert={ it.toLowerCase() }) String a()
@Option(convert={ it.toUpperCase() }) String b()
@Option(convert={ Date.parse("yyyy-MM-dd", it) }) Date d()
@Unparsed List remaining()
}以及使用该规范的示例
Date newYears = Date.parse("yyyy-MM-dd", "2016-01-01")
def argz = '''-a John -b Mary -d 2016-01-01 and some more'''.split()
def cli = new CliBuilder()
def options = cli.parseFromSpec(WithConvertI, argz)
assert options.a() == 'john'
assert options.b() == 'MARY'
assert options.d() == newYears
assert options.remaining() == ['and', 'some', 'more']带多个参数的选项
通过使用大于 1 的 args 值,也支持多个参数。有一个特殊的命名参数 valueSeparator,它也可以在处理多个参数时可选地使用。它允许在命令行上提供此类参数列表时,语法具有额外的灵活性。例如,提供逗号作为值分隔符允许在命令行上传递逗号分隔的值列表。
args 值通常是一个整数。它可以选择作为字符串提供。有两个特殊的字符串符号:`` 和 ``*``。``*`` 值表示 0 个或更多。`` 值表示 1 个或更多。``*`` 值与使用 ``+`` 并且同时将 ``optionalArg`` 值设置为 true 相同。
访问多个参数遵循一个特殊的约定。只需在您通常用于访问参数选项的属性后面添加一个“s”,您将检索所有提供的参数作为一个列表。因此,对于名为“a”的短选项,您可以使用 options.a 访问第一个“a”参数,并使用 options.as 访问所有参数的列表。短名称或长名称以“s”结尾是可以的,只要您不同时拥有没有“s”的单数变体。因此,如果 name 是您的多个参数选项之一,而 guess 是您的单个参数选项,那么使用 options.names 和 options.guess 就不会混淆。
以下是突出显示多个参数使用的摘录
// import CliBuilder not shown
def cli = new CliBuilder()
cli.a(args: 2, 'a-arg')
cli.b(args: '2', valueSeparator: ',', 'b-arg') (1)
cli.c(args: '+', valueSeparator: ',', 'c-arg') (2)
def options = cli.parse('-a 1 2 3 4'.split()) (3)
assert options.a == '1' (4)
assert options.as == ['1', '2'] (5)
assert options.arguments() == ['3', '4']
options = cli.parse('-a1 -a2 3'.split()) (6)
assert options.as == ['1', '2']
assert options.arguments() == ['3']
options = cli.parse(['-b1,2']) (7)
assert options.bs == ['1', '2']
options = cli.parse(['-c', '1'])
assert options.cs == ['1']
options = cli.parse(['-c1'])
assert options.cs == ['1']
options = cli.parse(['-c1,2,3'])
assert options.cs == ['1', '2', '3']| 1 | Args 值以字符串形式提供,并指定逗号值分隔符 |
| 2 | 允许一个或多个参数 |
| 3 | 两个命令行参数将作为“b”选项的参数列表提供 |
| 4 | 访问“a”选项的第一个参数 |
| 5 | 访问“a”选项的参数列表 |
| 6 | 为“a”选项指定两个参数的替代语法 |
| 7 | “b”选项的参数以逗号分隔值形式提供 |
作为使用*复数名称*方法访问多个参数的替代方法,您可以为选项使用基于数组的类型。在这种情况下,所有选项将始终通过数组返回,该数组通过正常的单数名称访问。我们将在接下来讨论类型时看到一个这样的示例。
通过对注解类成员(方法或属性)使用数组类型,还支持使用注解样式的选项定义来支持多个参数,如下例所示
interface ValSepI {
@Option(numberOfArguments=2) String[] a()
@Option(numberOfArgumentsString='2', valueSeparator=',') String[] b()
@Option(numberOfArgumentsString='+', valueSeparator=',') String[] c()
@Unparsed remaining()
}并按如下方式使用
def cli = new CliBuilder()
def options = cli.parseFromSpec(ValSepI, '-a 1 2 3 4'.split())
assert options.a() == ['1', '2']
assert options.remaining() == ['3', '4']
options = cli.parseFromSpec(ValSepI, '-a1 -a2 3'.split())
assert options.a() == ['1', '2']
assert options.remaining() == ['3']
options = cli.parseFromSpec(ValSepI, ['-b1,2'] as String[])
assert options.b() == ['1', '2']
options = cli.parseFromSpec(ValSepI, ['-c', '1'] as String[])
assert options.c() == ['1']
options = cli.parseFromSpec(ValSepI, ['-c1'] as String[])
assert options.c() == ['1']
options = cli.parseFromSpec(ValSepI, ['-c1,2,3'] as String[])
assert options.c() == ['1', '2', '3']类型和多个参数
以下是一个使用动态 API 参数定义样式,结合类型和多个参数的示例
def argz = '''-j 3 4 5 -k1.5,2.5,3.5 and some more'''.split()
def cli = new CliBuilder()
cli.j(args: 3, type: int[], 'j-arg')
cli.k(args: '+', valueSeparator: ',', type: BigDecimal[], 'k-arg')
def options = cli.parse(argz)
assert options.js == [3, 4, 5] (1)
assert options.j == [3, 4, 5] (1)
assert options.k == [1.5, 2.5, 3.5]
assert options.arguments() == ['and', 'some', 'more']| 1 | 对于数组类型,可以使用但不是必需的后缀“s” |
设置默认值
Groovy 允许使用 Elvis 操作符在变量使用时提供默认值,例如 String x = someVariable ?: 'some default'。但有时您希望将此类默认值作为选项规范的一部分,以最大程度地减少后续阶段的审问工作。CliBuilder 支持 defaultValue 属性来满足此场景。
以下是您可以使用动态 API 样式的方式
def cli = new CliBuilder()
cli.f longOpt: 'from', type: String, args: 1, defaultValue: 'one', 'f option'
cli.t longOpt: 'to', type: int, defaultValue: '35', 't option'
def options = cli.parse('-f two'.split())
assert options.hasOption('f')
assert options.f == 'two'
assert !options.hasOption('t')
assert options.t == 35
options = cli.parse('-t 45'.split())
assert !options.hasOption('from')
assert options.from == 'one'
assert options.hasOption('to')
assert options.to == 45同样,您可能希望使用注解样式进行此类规范。以下是使用接口规范的示例
interface WithDefaultValueI {
@Option(shortName='f', defaultValue='one') String from()
@Option(shortName='t', defaultValue='35') int to()
}其使用方式如下
def cli = new CliBuilder()
def options = cli.parseFromSpec(WithDefaultValueI, '-f two'.split())
assert options.from() == 'two'
assert options.to() == 35
options = cli.parseFromSpec(WithDefaultValueI, '-t 45'.split())
assert options.from() == 'one'
assert options.to() == 45在使用注解与实例时,您也可以使用 defaultValue 注解属性,尽管为属性(或支持字段)提供初始值可能同样简单。
与 TypeChecked 一起使用
使用 CliBuilder 的动态 API 样式本质上是动态的,但如果您想利用 Groovy 的静态类型检查功能,则有几种选择。首先,考虑使用注解样式,例如,这是一个接口选项规范
interface TypeCheckedI{
@Option String name()
@Option int age()
@Unparsed List remaining()
}它可以与 @TypeChecked 结合使用,如下所示
@TypeChecked
void testTypeCheckedInterface() {
def argz = "--name John --age 21 and some more".split()
def cli = new CliBuilder()
def options = cli.parseFromSpec(TypeCheckedI, argz)
String n = options.name()
int a = options.age()
assert n == 'John' && a == 21
assert options.remaining() == ['and', 'some', 'more']
}其次,动态 API 样式有一个特性提供了一些支持。定义语句本质上是动态的,但实际上返回了一个值,我们在之前的示例中忽略了该值。返回的值实际上是 TypedOption<Type>,特殊的 getAt 支持允许使用类型化选项查询选项,例如 options[savedTypeOption]。因此,如果您在代码的非类型检查部分中有类似的语句
def cli = new CliBuilder()
TypedOption<Integer> age = cli.a(longOpt: 'age', type: Integer, 'some age option')那么,以下语句可以在代码的单独部分中进行类型检查
def args = '--age 21'.split()
def options = cli.parse(args)
int a = options[age]
assert a == 21最后,CliBuilder 还提供了一个额外的便利方法,甚至允许对定义部分进行类型检查。这是一种稍微冗长的方法调用。不使用方法调用中的短名称(*opt* 名称),而是使用固定的名称 option 并将 opt 值作为属性提供。您还必须直接指定类型,如以下示例所示
import groovy.cli.TypedOption
import groovy.transform.TypeChecked
@TypeChecked
void testTypeChecked() {
def cli = new CliBuilder()
TypedOption<String> name = cli.option(String, opt: 'n', longOpt: 'name', 'name option')
TypedOption<Integer> age = cli.option(Integer, longOpt: 'age', 'age option')
def argz = "--name John --age 21 and some more".split()
def options = cli.parse(argz)
String n = options[name]
int a = options[age]
assert n == 'John' && a == 21
assert options.arguments() == ['and', 'some', 'more']
}高级 CLI 用法
|
注意 高级 CLI 功能
|
Apache Commons CLI
例如,以下是一些利用 Apache Commons CLI 分组机制的代码
import org.apache.commons.cli.*
def cli = new CliBuilder()
cli.f longOpt: 'from', 'f option'
cli.u longOpt: 'until', 'u option'
def optionGroup = new OptionGroup()
optionGroup.with {
addOption cli.option('o', [longOpt: 'output'], 'o option')
addOption cli.option('d', [longOpt: 'directory'], 'd option')
}
cli.options.addOptionGroup optionGroup
assert !cli.parse('-d -o'.split()) (1)| 1 | 解析将失败,因为一个组中一次只能使用一个选项。 |
Picocli
以下是 CliBuilder 的 picocli 版本中可用的一些功能。
新属性:errorWriter
当您的应用程序用户提供无效命令行参数时,CliBuilder 会将错误消息和使用帮助消息写入 stderr 输出流。它不使用 stdout 流,以防止程序输出用作另一个进程的输入时解析错误消息。您可以通过将 errorWriter 设置为不同的值来自定义目标。
另一方面,CliBuilder.usage() 将使用帮助消息打印到 stdout 流。这样,当用户请求帮助(例如,使用 --help 参数)时,他们可以将输出通过管道传输到 less 或 grep 等实用程序。
您可以为测试指定不同的写入器。请注意,为了向后兼容,将 writer 属性设置为不同的值将同时将 writer 和 errorWriter 设置为指定的写入器。
ANSI 颜色
CliBuilder 的 picocli 版本会自动在支持的平台上以 ANSI 颜色渲染使用帮助消息。如果需要,您可以自定义此功能。(示例如下。)
新属性:name
和以前一样,您可以使用 usage 属性设置使用帮助消息的提要。您可能对一个小改进感兴趣:如果您只设置命令 name,将自动生成一个提要,重复元素后跟 …,可选元素用 [ 和 ] 括起来。(示例如下。)
新属性:usageMessage
此属性公开了底层 picocli 库中的 UsageMessageSpec 对象,该对象可以对使用帮助消息的各个部分进行细粒度控制。例如
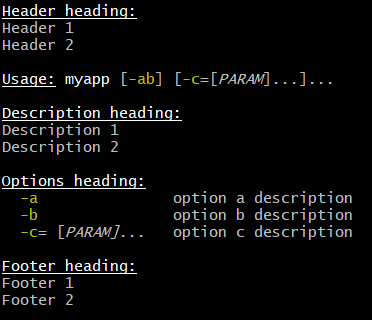
def cli = new CliBuilder()
cli.name = "myapp"
cli.usageMessage.with {
headerHeading("@|bold,underline Header heading:|@%n")
header("Header 1", "Header 2") // before the synopsis
synopsisHeading("%n@|bold,underline Usage:|@ ")
descriptionHeading("%n@|bold,underline Description heading:|@%n")
description("Description 1", "Description 2") // after the synopsis
optionListHeading("%n@|bold,underline Options heading:|@%n")
footerHeading("%n@|bold,underline Footer heading:|@%n")
footer("Footer 1", "Footer 2")
}
cli.a('option a description')
cli.b('option b description')
cli.c(args: '*', 'option c description')
cli.usage()输出如下
属性:parser
parser 属性提供了对 picocli ParserSpec 对象的访问,该对象可用于自定义解析器行为。
当控制解析器的 CliBuilder 选项不够细粒度时,这会很有用。例如,为了与 CliBuilder 的 Commons CLI 实现向后兼容,默认情况下,当遇到未知选项时,CliBuilder 会停止查找选项,随后的命令行参数被视为位置参数。CliBuilder 提供了 stopAtNonOption 属性,通过将其设置为 false,您可以使解析器更严格,因此未知选项会导致 error: Unknown option: '-x'。
但是,如果您想将未知选项视为位置参数,并且仍然将随后的命令行参数作为选项处理,该怎么办?
这可以通过 parser 属性来实现。例如
def cli = new CliBuilder()
cli.parser.stopAtPositional(false)
cli.parser.unmatchedOptionsArePositionalParams(true)
// ...
def opts = cli.parse(args)
// ...有关详细信息,请参阅文档。
映射选项
最后,如果您的应用程序的选项是键值对,您可能对 picocli 对映射的支持感兴趣。例如
import java.util.concurrent.TimeUnit
import static java.util.concurrent.TimeUnit.DAYS
import static java.util.concurrent.TimeUnit.HOURS
def cli = new CliBuilder()
cli.D(args: 2, valueSeparator: '=', 'the old way') (1)
cli.X(type: Map, 'the new way') (2)
cli.Z(type: Map, auxiliaryTypes: [TimeUnit, Integer].toArray(), 'typed map') (3)
def options = cli.parse('-Da=b -Dc=d -Xx=y -Xi=j -ZDAYS=2 -ZHOURS=23'.split())(4)
assert options.Ds == ['a', 'b', 'c', 'd'] (5)
assert options.Xs == [ 'x':'y', 'i':'j' ] (6)
assert options.Zs == [ (DAYS as TimeUnit):2, (HOURS as TimeUnit):23 ] (7)| 1 | 以前,key=value 对被拆分为多个部分并添加到列表中 |
| 2 | Picocli 映射支持:只需将 Map 指定为选项的类型 |
| 3 | 您甚至可以指定映射元素的类型 |
| 4 | 为了比较,让我们为每个选项指定两个键值对 |
| 5 | 以前,所有键值对都最终在一个列表中,由应用程序处理此列表 |
| 6 | Picocli 将键值对作为 Map 返回 |
| 7 | 映射的键和值都可以是强类型 |
控制 Picocli 版本
要使用特定版本的 picocli,请在构建配置中添加对该版本的依赖。如果使用预安装的 Groovy 版本运行脚本,请使用 @Grab 注解来控制 CliBuilder 中使用的 picocli 版本。
@GrabConfig(systemClassLoader=true)
@Grab('info.picocli:picocli:4.2.0')
import groovy.cli.picocli.CliBuilder
def cli = new CliBuilder()8.1.12. ObjectGraphBuilder
ObjectGraphBuilder 是一个用于构建遵循 JavaBean 约定的任意 bean 图的构建器。它特别适用于创建测试数据。
让我们从属于您领域的一系列类开始
package com.acme
class Company {
String name
Address address
List employees = []
}
class Address {
String line1
String line2
int zip
String state
}
class Employee {
String name
int employeeId
Address address
Company company
}然后使用 ObjectGraphBuilder 构建一个拥有三名员工的 Company 就像这样简单
def builder = new ObjectGraphBuilder() (1)
builder.classLoader = this.class.classLoader (2)
builder.classNameResolver = "com.acme" (3)
def acme = builder.company(name: 'ACME') { (4)
3.times {
employee(id: it.toString(), name: "Drone $it") { (5)
address(line1:"Post street") (6)
}
}
}
assert acme != null
assert acme instanceof Company
assert acme.name == 'ACME'
assert acme.employees.size() == 3
def employee = acme.employees[0]
assert employee instanceof Employee
assert employee.name == 'Drone 0'
assert employee.address instanceof Address| 1 | 创建一个新的对象图构建器 |
| 2 | 设置将解析类的类加载器 |
| 3 | 设置要解析的类的基本包名 |
| 4 | 创建 Company 实例 |
| 5 | 拥有 3 个 Employee 实例 |
| 6 | 每个实例都有一个不同的 Address |
在幕后,对象图构建器
-
将尝试将节点名称匹配到
Class,使用需要包名的默认ClassNameResolver策略 -
然后将使用调用无参数构造函数的默认
NewInstanceResolver策略创建相应类的实例 -
解析嵌套节点的父/子关系,涉及另外两种策略
-
RelationNameResolver将返回子在父中的属性名,以及父在子中的属性名(如果有,在这种情况下,Employee有一个父属性,恰当地命名为company) -
ChildPropertySetter将把子插入到父中,同时考虑子是否属于Collection(在这种情况下,employees应该是Company中Employee实例的列表)。
-
所有 4 种策略都有一个默认实现,如果代码遵循编写 JavaBeans 的常规约定,则按预期工作。如果您的任何 bean 或对象不遵循约定,您可以插入自己的每个策略实现。例如,假设您需要构建一个不可变类
@Immutable
class Person {
String name
int age
}然后,如果您尝试使用构建器创建 Person
def person = builder.person(name:'Jon', age:17)它将在运行时失败,并显示
Cannot set readonly property: name for class: com.acme.Person
可以通过更改新实例策略来修复此问题
builder.newInstanceResolver = { Class klazz, Map attributes ->
if (klazz.getConstructor(Map)) {
def o = klazz.newInstance(attributes)
attributes.clear()
return o
}
klazz.newInstance()
}ObjectGraphBuilder 支持每个节点的 ID,这意味着您可以在构建器中存储对节点的引用。当多个对象引用同一实例时,这很有用。因为名为 id 的属性在某些领域模型中可能具有业务意义,所以 ObjectGraphBuilder 有一个名为 IdentifierResolver 的策略,您可以对其进行配置以更改默认名称值。同样的情况也可能发生在用于引用先前保存实例的属性上,名为 ReferenceResolver 的策略将返回适当的值(默认值为 `refId`)
def company = builder.company(name: 'ACME') {
address(id: 'a1', line1: '123 Groovy Rd', zip: 12345, state: 'JV') (1)
employee(name: 'Duke', employeeId: 1, address: a1) (2)
employee(name: 'John', employeeId: 2 ){
address( refId: 'a1' ) (3)
}
}| 1 | 可以使用 id 创建地址 |
| 2 | 员工可以直接使用其 ID 引用地址 |
| 3 | 或使用对应地址 id 的 refId 属性 |
值得一提的是,您不能修改被引用 bean 的属性。
8.1.13. JmxBuilder
有关详细信息,请参阅使用 JMX - JmxBuilder。
8.1.14. FileTreeBuilder
groovy.util.FileTreeBuilder 是一个用于根据规范生成文件目录结构的构建器。例如,要创建以下树
src/
|--- main
| |--- groovy
| |--- Foo.groovy
|--- test
|--- groovy
|--- FooTest.groovy
您可以使用 FileTreeBuilder 如下所示
tmpDir = File.createTempDir()
def fileTreeBuilder = new FileTreeBuilder(tmpDir)
fileTreeBuilder.dir('src') {
dir('main') {
dir('groovy') {
file('Foo.groovy', 'println "Hello"')
}
}
dir('test') {
dir('groovy') {
file('FooTest.groovy', 'class FooTest extends groovy.test.GroovyTestCase {}')
}
}
}为了检查一切是否按预期工作,我们使用以下断言
assert new File(tmpDir, '/src/main/groovy/Foo.groovy').text == 'println "Hello"'
assert new File(tmpDir, '/src/test/groovy/FooTest.groovy').text == 'class FooTest extends groovy.test.GroovyTestCase {}'FileTreeBuilder 还支持简写语法
tmpDir = File.createTempDir()
def fileTreeBuilder = new FileTreeBuilder(tmpDir)
fileTreeBuilder.src {
main {
groovy {
'Foo.groovy'('println "Hello"')
}
}
test {
groovy {
'FooTest.groovy'('class FooTest extends groovy.test.GroovyTestCase {}')
}
}
}这会生成与上面相同的目录结构,如下面的断言所示
assert new File(tmpDir, '/src/main/groovy/Foo.groovy').text == 'println "Hello"'
assert new File(tmpDir, '/src/test/groovy/FooTest.groovy').text == 'class FooTest extends groovy.test.GroovyTestCase {}'8.2. 创建构建器
虽然 Groovy 有许多内置构建器,但构建器模式非常常见,您无疑最终会遇到内置构建器无法满足的构建需求。好消息是您可以构建自己的构建器。您可以依靠 Groovy 的元编程功能从头开始做所有事情。或者,BuilderSupport 和 FactoryBuilderSupport 类使设计自己的构建器变得更加容易。
8.2.1. BuilderSupport
构建构建器的一种方法是继承 BuilderSupport。通过这种方法,通常的想法是覆盖多个*生命周期*方法中的一个或多个,包括 setParent、nodeCompleted 以及 BuilderSupport 抽象类中的部分或全部 createNode 方法。
例如,假设我们要创建一个用于跟踪运动训练计划的构建器。每个计划都由多个组组成,每个组都有自己的步骤。一个步骤本身可能是一组更小的步骤。对于每个 set 或 step,我们可能希望记录所需的 distance(或 time),是否将步骤 repeat 一定次数,是否在每个步骤之间休息等等。
为了本示例的简单性,我们将使用映射和列表来捕获训练程序。一个组有一个步骤列表。repeat 次数或 distance 等信息将在每个步骤和组的属性映射中进行跟踪。
构建器实现如下
-
覆盖几个
createNode方法。我们将创建一个捕获集合名称、空步骤列表以及可能的一些属性的映射。 -
每当我们完成一个节点时,我们都会将该节点添加到父节点的步骤列表中(如果有)。
代码如下所示
class TrainingBuilder1 extends BuilderSupport {
protected createNode(name) {
[name: name, steps: []]
}
protected createNode(name, Map attributes) {
createNode(name) + attributes
}
void nodeCompleted(maybeParent, node) {
if (maybeParent) maybeParent.steps << node
}
// unused lifecycle methods
protected void setParent(parent, child) { }
protected createNode(name, Map attributes, value) { }
protected createNode(name, value) { }
}接下来,我们将编写一个小的辅助方法,该方法递归地累加所有子步骤的距离,并根据需要考虑重复步骤。
def total(map) {
if (map.distance) return map.distance
def repeat = map.repeat ?: 1
repeat * map.steps.sum{ total(it) }
}最后,我们现在可以使用我们的构建器和辅助方法来创建一个游泳训练计划并检查其总距离
def training = new TrainingBuilder1()
def monday = training.swimming {
warmup(repeat: 3) {
freestyle(distance: 50)
breaststroke(distance: 50)
}
endurance(repeat: 20) {
freestyle(distance: 50, break: 15)
}
warmdown {
kick(distance: 100)
choice(distance: 100)
}
}
assert 1500 == total(monday)8.2.2. FactoryBuilderSupport
构建构建器的第二种方法是继承 FactoryBuilderSupport。这个构建器与 BuilderSupport 有相似的目标,但增加了额外的功能以简化领域类构建。
通过这种方法,通常的想法是覆盖多个*生命周期*方法中的一个或多个,包括 resolveFactory、nodeCompleted 和 postInstantiate 方法,这些方法来自 FactoryBuilderSupport 抽象类。
我们将使用与之前的 BuilderSupport 示例相同的示例;一个跟踪运动训练计划的构建器。
在此示例中,我们不使用映射和列表来捕获训练程序,而是使用一些简单的领域类。
构建器实现如下
-
覆盖
resolveFactory方法以返回一个特殊工厂,该工厂通过将我们迷你 DSL 中使用的名称大写来返回类。 -
每当我们完成一个节点时,我们都会将该节点添加到父节点的步骤列表中(如果有)。
代码,包括特殊工厂类的代码,如下所示
import static org.apache.groovy.util.BeanUtils.capitalize
class TrainingBuilder2 extends FactoryBuilderSupport {
def factory = new TrainingFactory(loader: getClass().classLoader)
protected Factory resolveFactory(name, Map attrs, value) {
factory
}
void nodeCompleted(maybeParent, node) {
if (maybeParent) maybeParent.steps << node
}
}
class TrainingFactory extends AbstractFactory {
ClassLoader loader
def newInstance(FactoryBuilderSupport fbs, name, value, Map attrs) {
def clazz = loader.loadClass(capitalize(name))
value ? clazz.newInstance(value: value) : clazz.newInstance()
}
}我们不使用列表和映射,而是使用一些简单的领域类和相关的特性
trait HasDistance {
int distance
}
trait Container extends HasDistance {
List steps = []
int repeat
}
class Cycling implements Container { }
class Interval implements Container { }
class Sprint implements HasDistance {}
class Tempo implements HasDistance {}就像 BuilderSupport 示例一样,拥有一个辅助方法来计算训练期间覆盖的总距离会很有用。实现与我们之前的示例非常相似,但已调整为与我们新定义的特性很好地配合。
def total(HasDistance c) {
c.distance
}
def total(Container c) {
if (c.distance) return c.distance
def repeat = c.repeat ?: 1
repeat * c.steps.sum{ total(it) }
}最后,我们现在可以使用新的构建器和辅助方法来创建自行车训练计划并检查其总距离
def training = new TrainingBuilder2()
def tuesday = training.cycling {
interval(repeat: 5) {
sprint(distance: 400)
tempo(distance: 3600)
}
}
assert 20000 == total(tuesday)